{kind=link}
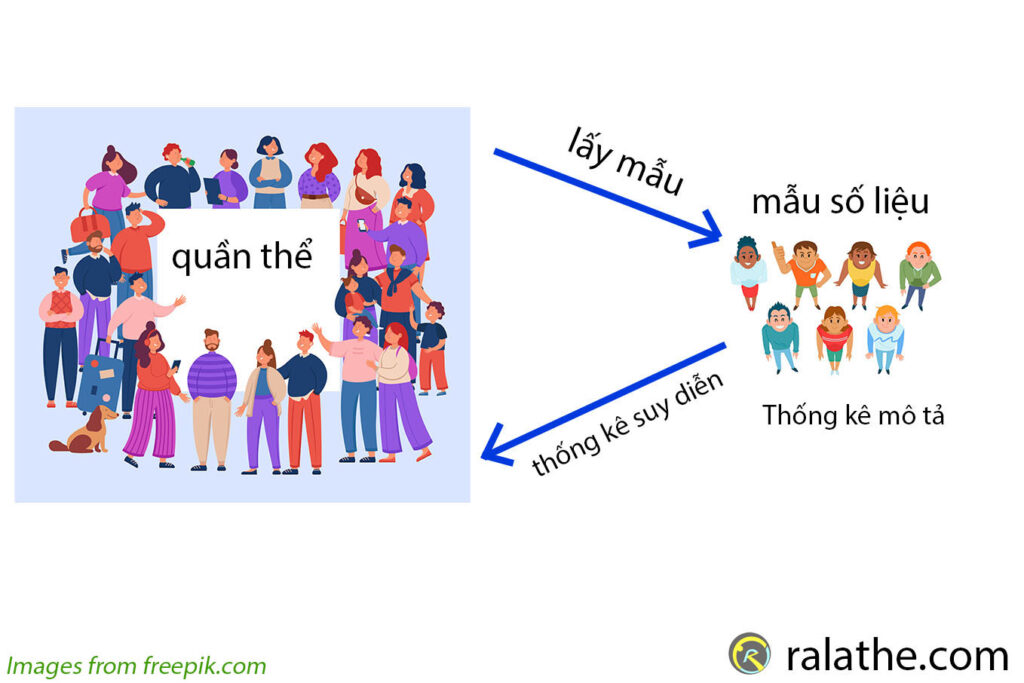
Trong thống kê cho khoa học dữ liệu, thống kê suy diễn là một phần hết sức quan trọng, giúp chúng ta sử dụng những thông tin giới hạn của dữ liệu mẫu (sample) để suy ra những đặc điểm của quần thể (population). Vì một lý do hết sức đơn giản, chúng ta không thể nào có thể thu thập toàn bộ dữ liệu của dữ liệu cha được.
Mục lục bài viết
Thống kê suy diễn trong thống kê cho khoa học dữ liệu
Thống kê suy diễn (inferential statistics) giúp chúng ta biết được những đặc tính của quần thể (population) từ những thông tin ít ỏi của dữ liệu mẫu (sample).
Chẳng hạn như, khi tính chiều cao trung bình của tất cả học sinh cấp 1 trên toàn Việt Nam (quần thể), chúng ta không thể nào đo được toàn bộ chiều cao của tất cả học sinh được.
Chúng ta chỉ có thể thu thập một dữ liệu mẫu nhất định và từ đó suy ra cho toàn bộ quần thể. Đó chính là thế mạnh của thống kê suy diễn trong thống kê cho khoa học dữ liệu!

>>> Xem thêm: phương pháp thu thập mẫu số liệu trong thống kê
Thống kê mô tả V.S. thống kê suy diễn
Như chúng ta đã tìm hiểu ở 7 bài trước (phần 1) thống kê mô tả giúp chúng ta mô tả dữ liệu và có cái nhìn sâu hơn về mẫu dữ liệu của mình.
Sử dụng thống kê mô tả giúp chúng ta xác định được:
- Giá trị đại diện cho mẫu số liệu
- Phân tán của các số liệu xung quanh giá trị đại diện này
- Các đặc điểm phân bố của giá trị trong mẫu số liệu
Trong khi đó, thống kê suy diễn giúp chúng ta xác định:
- đặc tính của quần thể thông qua giá trị tính toán của mẫu số liệu – Ước lượng (estimation)
- So sánh các quần thể với nhau thông qua các mẫu số liệu của chúng – Kiểm định (statistical test)
Ứng dụng của thống kê suy diễn
Như đã nói ở trên, trong thống kê cho khoa học dữ liệu, thống kê suy diễn có thể dùng để ước lượng và kiểm định một giả thuyết thống kê. Chúng ta sẽ đi sâu vào những phần này trong những bài học sau.
Trong bài này, chúng ta chỉ giới thiệu các khái niệm cơ bản nhất làm nền tảng cho những bài học sau.
Ước lượng thông số của quần thể từ một mẫu
Khi trích xuất dữ liệu mẫu từ dữ liệu cha (hay quần thể) và dùng chúng để ước lượng các thông số của dữ liệu cha này, thì chắc chắn sẽ có một sự sai khác giữa những thông số, đó chính là sai số thống kê (sampling error).
Khi thực hiện thống kê suy diễn, chúng ta sẽ ước lượng những thông số này sao cho sai số thống kê nằm trong khoảng chấp nhận được (bằng cách nào, từ từ chúng ta sẽ bàn tới 🙃🙃🙃).
Có hai phương pháp ước lượng phổ biến là ước lượng điểm (point estimate) và ước lượng khoảng (interval estimate).
Ước lượng điểm
Ước lượng điểm, như cái tên của nó, là ước lượng tham số của quần thể bằng một thông số của mẫu. Chẳng hạn, chúng ta ước lượng giá trị trung bình của mẫu chính là giá trị trung bình của quần thể đó.
Vì tính chất này mà ước lượng điểm thường không chắc chắn và ít được sử dụng trong thống kê cho khoa học dữ liệu hay trong thực tế.
Ước lượng khoảng
Ước lượng khoảng giúp bạn đưa ra một khoảng giá trị có thể chứa thông số của quần thể. Thường dùng nhất là khoảng tin cậy (confidence interval).
Khoảng tin cậy (CI) là phạm vi các giá trị có thể chứa đựng một tham số của quần thể. Như đã nói ở trên, khi ước lượng sẽ có sai số thống kê, CI giúp chúng ta làm cho sai số thống kê này nằm trong khoảng chấp nhận được. Mỗi CI sẽ có một độ tin cậy (confidence level).
Độ tin cậy cho bạn biết xác suất (theo phần trăm) mà thông số của quần thể sẽ lại nằm trong khoảng tin cậy khi bạn lặp lại nghiên cứu lần nữa.
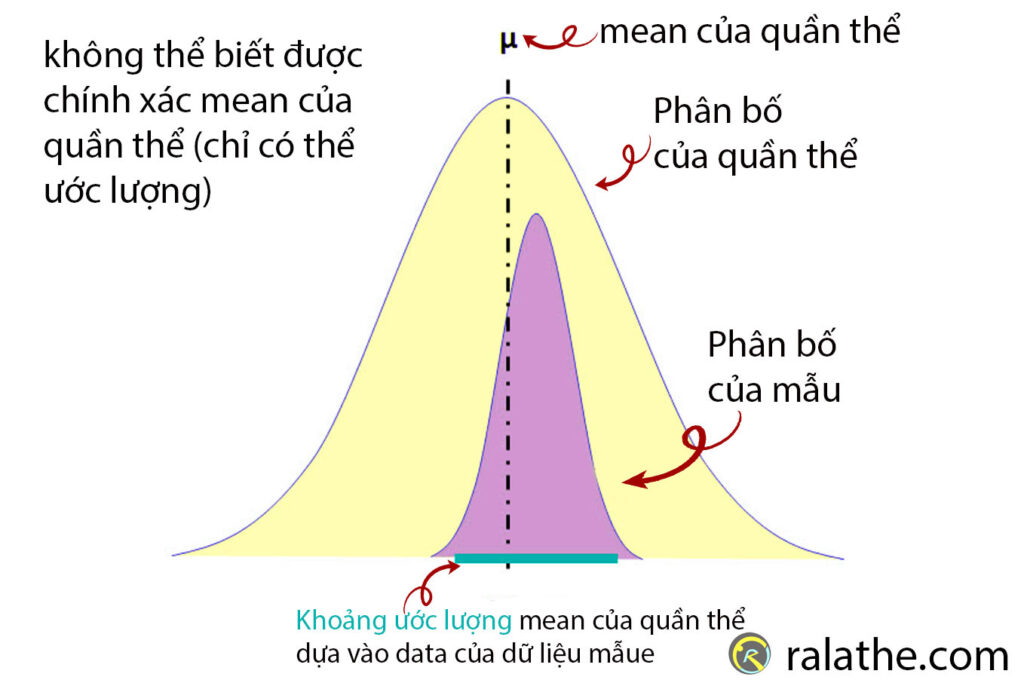
Chẳng hạn, khi nói khoảng tin cậy 95% nghĩa là khi bạn lặp lại cùng một thí nghiệm với một mẫu mới 100 lần, thì có 95 lần thông số của quần thể sẽ nằm trong khoảng mà bạn chọn.
Tuy nhiên, khoảng tin cậy không cho biết chính xác thông số của quần thể (vì nó là một khoảng).
Kiểm định giả thuyết thống kê
Mục đích của việc kiểm định giả thuyết thống kê trong khoa học dữ liệu là để so sánh các quần thể cũng như đánh giá mối quan hệ giữa các biến của quần thể thông qua việc lấy mẫu.
Như đã nói ở trên, việc biết được chính xác thông số của một quần thể là điều không thể thực hiện.
Chính vì thế, để có thể làm được điều này cần dựa vào các mẫu dữ liệu thu thập được từ quần thể trên.
Kiểm định các giả thuyết thống kê được thực hiện thông qua kiểm định thống kê (statistical tests). Các kiểm định này cũng giúp ta đánh giá sai số thống kê và đưa ra những nhận định thích hợp.
Có 2 loại kiểm định, đó là kiểm định có tham số (parametric tests) và kiểm định phi tham số (non-parametric tests). Thông thường thì kiểm định có tham số có hiệu quả hơn vì chúng cho chúng ta đánh giá những ảnh hưởng nếu có.
Kiểm định có tham số cần tuân theo các giả định sau:
- Mẫu được từ quần thể tuân theo phân phối chuẩn
- Mẫu phải đủ lớn để phản ánh đúng tính chất của quần thể
- Các nhóm được so sánh phải có phương sai tương tự nhau.
Nếu không tuân theo được bất kỳ một trong các giả định trên, ta phải thực hiện kiểm định phi tham số.
Kiểm định phi tham số còn được gọi là “kiểm định không phân phối” (distribution-free tests). Không cần có bất kỳ giả định nào cho loại này.
Các loại kiểm định phổ biến trong thống kê cho khoa học dữ liệu
Kiểm định thống kê có thể được thực hiện dưới một trong ba hình thức:
- Kiểm định so sánh (comparison tests)
- Kiểm định tương quan (Correlation tests)
- Kiểm định hồi quy (Regression tests)
Kiểm định so sánh
Trong thống kê cho khoa học dữ liệu, kiểm định so sánh cho biết có hay không sự khác biệt của mean, median, điểm xếp hạng (ranking score) giữa hai hay nhiều nhóm.
Các kiểm định so sánh có thể dùng như bảng sau:
| Kiểm định so sánh | Có thông số hay không? | So sánh cái gì? | Số lượng mẫu |
| t-test | có | mean | 2 |
| ANOVA | có | mean | 3+ |
| Mood’s median | không | median | 2+ |
| Wilcoxon signed-rank | không | phân bố | 2 |
| Wilcoxon rank-sum (Mann-Whitney U) | không | tổng xếp hạng (sums of rankings) | 2 |
| Kruskal-Wallis H | không | xếp hạng mean | 3+ |
Để quyết định nên sử dụng loại kiểm định nào, bạn cần cân nhắc xem dữ liệu của mình có thõa mản yêu cầu như có tham số hay không, số lượng mẫu, thang đo của bạn. (nominal, ordinal, interval, ratio).
Kiểm định tương quan trong thống kê cho khoa học dữ liệu
Như tên gọi, kiểm định tương quan cho biết mức độ tương quan của hai thông số.
Các loại tương quan bao gồm:
| Tương quan | Có thông số không? | Biến |
| Pearson’s r | có | Nominal/ordinal |
| Spearman’s r | không | Ordinal/interval/ratio |
| Kendell’s r | không | Ordinal/interval/ratio |
| Chi square test of independence | không | Nominal/ordinal |
Kiểm định hồi quy
Hồi quy dùng để kiểm định liệu sự thay đổi của biến dự đoán có ảnh hưởng đến sự thay đổi của biến đầu ra hay không. Tùy vào số lượng biến, loại biến mà ta sử dụng hồi quy cho phù hợp.
Kiểm định hồi quy là một trong những kiểm định thường dùng nhất trong thống kê cho khoa học dữ liệu, đặc biệt là máy học – machine learning – giúp ta dự đoán một kết quả mong muốn.
Kiểm định hồi quy thường dùng gồm có:
| Kiểm định hồi quy | Số lượng biến dự đoán | Số lượng kết quả |
| Hồi quy tuyến tính đơn (simple linear regression) | 1 (interval/ratio) | 1 (interval/ratio) |
| Hồi quy tuyến tính đa biến (multiple linear regression) | 2+ (interval/ratio) | 1 (interval/ratio) |
| Hồi quy logarit (logistic regression) | 1+ (bất cứ loại nào) | 1 (nhị phân: yes/no, nam/nữ,…) |
| Hồi quy nominal | 1+ (bất cứ loại nào) | 1 (nominal) |
| Hồi quy ordinal | 1+ (bất cứ loại nào) | 1 (ordinal) |
Tổng kết
Thống kê suy diễn là một khía cạnh quan trong trong thống kê cho khoa học dữ liệu. Nó cho phép chúng ta phân tích những đặc tính của cả quần thể thông qua những mẫu số liệu nhỏ hơn.
Thống kê suy diễn có thể chia ra thành ước lượng và kiểm định. Mỗi loại lại được phân chia thành những loại nhỏ hơn tùy vào mục đích làm thống kê.
Tóm lại, hãy thật giỏi thống kê suy diễn bạn nhé!