{kind=link}
Trong bài thống kê cho khoa học dữ liệu trước, chúng ta đã biết được trong thống kê suy diễn có 2 loại là ước lượng và kiểm định. Bài hôm nay chúng ta sẽ đi sâu hơn vào phần ước lượng, cụ thể là ước lượng khoảng giá trị trung bình của quần thể.
Mục lục bài viết
- 1 Giải thích về ước lượng khoảng trong thống kê cho khoa học dữ liệu
- 2 Ví dụ về ước lượng giá trị trung bình – ước lượng khoảng
- 3 Tổng kết
Giải thích về ước lượng khoảng trong thống kê cho khoa học dữ liệu
Ước lượng khoảng giá trị trung bình của quần thể rất hay được sử dụng trong cuộc sống.
Chẳng hạn như thống kê chiều cao trung bình của nam giới cả nước. Hay đánh giá độ bền của sản phẩm sản xuất được của một nhà máy. Hay vật giá trung bình hiện nay…
Phân bố của mẫu chính là chìa khóa
Nếu biết được phân bố mẫu trông như thế nào thì ta sẽ dễ dàng thiết lập khoảng tin cậy (CI) và tính toán giá trị.
Từ đó sử dụng giá trị trung bình để tính toán khoảng trung bình của dữ liệu cha hay quần thể.
Các bước thực hiện ước lượng khoảng giá trị trung bình
Bước 1: tạo dữ liệu mẫu
Ta sẽ tạo mẫu dữ liệu bằng cách trích xuất ngẫu nhiên từ quần thể. Gọi giá trị trung bình của quần thể là [math]\mu[/math], độ lớn của dữ liệu mẫu là [math]n[/math].
Bước 2: Tính công thức ước lượng từ dữ liệu mẫu.
Ta đã biết trong bài 3.2 giá trị trung bình của dữ liệu mẫu là công thức ước lượng bất thiên của giá trị trung bình [math]\mu[/math] của quần thể.
Ta gọi giá trị trung bình của dữ liệu mẫu là [math]\bar{x}[/math]
Bước 3: Xác định khoảng tin cậy.
Thông thường ta có thể xác định khoảng tin cậy là 95%. Tùy từng trường hợp mà ta sẽ xác định khoảng tin cậy cho phù hợp.
Bước 4: Xem xét phân bố mẫu.
Đây là một việc quan trọng trong thống kê cho khoa học dữ liệu.
Giá trị trung bình của dữ liệu mẫu sẽ có phân bố như thế nào?
Trong bài trước, ta đã biết trung bình của phân bố mẫu của giá trị trung bình mẫu [math]\bar{x}[/math] sẽ trùng khớp với giá trị trung bình của quần thể [math]\mu[/math].
Với [math]\sigma[/math] là độ lệch chuẩn của quần thể, thì phân tán của phân bố mẫu của giá trị trung bình mẫu [math]\bar{x}[/math] sẽ là:
[math]\frac{\sigma^2}{n}[/math].
Và độ lệch chuẩn sẽ là căn của phân tán:
[math]\frac{\sigma}{\sqrt{n}}[/math].
Điều quan trọng cần nhớ ở đây là phân tán của quần thể là chưa biết!
Nếu quần thể có phân bố chuẩn, thì tất nhiên mẫu dữ liệu của chúng ta cũng sẽ có phân bố chuẩn. Nhưng nếu quần thể không có phân bố chuẩn thì sao?
Lúc này ta cần lấy mẫu sao cho độ lớn của [math]n[/math] là đủ lớn. Khi đó, phân bố mẫu của [math]\bar{x}[/math] sẽ gần giống hay xấp xỉ với phân bố chuẩn. Đây chính là định lý giới hạn trung tâm mà chúng ta đã bàn tới ở bài 3.2 trong series thống kê cho khoa học dữ liệu này.
Nói nãy giờ, chúng ta cần nắm được 2 ý sau:
- Nếu quần thể có phân bố chuẩn thì không cần quan tâm đến độ lớn [math]n[/math] của mẫu, phân bố mẫu của [math]\bar{x}[/math] chắc chắn sẽ là phân bố chuẩn.
- Nếu quần thể không có phân bố chuẩn nhưng chỉ cần [math]n[/math] đủ lớn thì phân bố mẫu của [math]\bar{x}[/math] sẽ gần giống với phân bố chuẩn.
Nếu quần thể không có phân bố chuẩn nhưng chỉ cần [math]n[/math] đủ lớn thì phân bố mẫu của [math]\bar{x}[/math] sẽ gần giống với phân bố chuẩn.
Ở đây, hãy xem [math]n[/math] là đủ lớn để phân bố mẫu của [math]\bar{x}[/math] là phân bố chuẩn với giá trị trung bình là [math]\mu[/math] và phương sai là [math]\frac{\sigma^2}{n}[/math]. Độ tin cậy được lấy ở đây là 95%. Khi đó khoảng giá trị của điểm [math]z[/math] sẽ là -1/96 ~ 1.96. Điểm [math]z[/math] lúc này sẽ được chuẩn hóa theo công thức:
[math]z=\frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}}[/math]
Bước 5: Tính toán giá trị của [math]\mu[/math] trong khoảng 95%.
Trong khoảng 95% thì [math]z[/math] sẽ nằm trong khoảng [math]-1.96 < z < 1.96[/math]. Hay:
[math]-1.96 < \frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}} < 1.96[/math]
Từ đây ta có thể ước lượng được [math]\mu[/math] của quần thể với độ tin cậy là 95%.
Tuy nhiên, vì không biết độ độ lệch chuẩn [math]\sigma[/math] của quần thể, nên thông thường [math]\sigma[/math] sẽ được ước lượng bằng độ lệch chuẩn bất biến thiên (là căn bậc hai của phân tán bất biến thiên) của dữ liệu mẫu. Vì khi [math]n[/math] đủ lớn thì phân bố của mẫu sẽ gần phân bố chuẩn. Công thức lúc này sẽ là:
[math]-1.96 < \frac{\bar{x}-\mu}{\frac{s’}{\sqrt{n}}} < 1.96[/math]
hay:
[math]\bar{x}-1.96\frac{s’}{\sqrt{n}} < \mu < \bar{x}+1.96\frac{s’}{\sqrt{n}}[/math]
với:
[math]s’^2=\frac{1}{n-1}\displaystyle\sum_{i=1}^{n}(x_i-\bar{x})^2[/math]
Tuy nhiên, vì ta đã dùng độ lệch chuẩn bất biến thiên thay cho [math]\sigma[/math] nên phân bố của mẫu không còn là phân bố chuẩn nữa, hình dạng phân bố đã biến đổi đi một chút. Người ta gọi nó là phân bố t. Nhớ rằng, khi [math]n[/math] đủ lớn thì phân bố t sẽ tiệm cận phân bố chuẩn.
Ví dụ về ước lượng giá trị trung bình – ước lượng khoảng
Bài này chúng ta sẽ dùng dữ liệu thực tế để lấy ví dụ. Các bạn có thể tìm thấy những kiểu dữ liệu này rất nhiều trên kaggle.com. Trong bài thống kê cho khoa học dữ liệu lần này, dataset (dữ liệu) mà chúng ta sẽ sử dụng là dữ liệu về thu nhập trung bình ở Mỹ.
Dataset sẽ sử dụng cho ước lượng giá trị trung bình này
Các bạn có thể dataset này tại đây: US Household income statistic.
Chúng ta sẽ dùng python để thực hiện ví dụ này:
import pandas as pd
import seaborn as sb
%matplotlib inline
df = pd.read_csv("./data/kaggle_income.csv", encoding="ISO-8859-1")
df.head()Nếu không dùng encoding thì sẽ có lỗi như sau:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf1 in position 20530: invalid continuation byteLỗi này phát sinh có thể do dataset có ký tự mà utf-8 không thể đọc được. Do đó, để có thể đọc được toàn bộ dữ liệu, chúng ta cần thêm encoding. Ở đây, encoding bằng “ISO-8859-1“ có thể giúp ta đọc được toàn bộ dữ liệu.
Lúc này dataset của chúng ta sẽ hiện ra như sau:

mỗi một record (dòng) sẽ đại diện cho 1 bang và thu nhập trung bình của hộ gia đình trong bang đó được biểu hiện qua cột Mean.
>>>> Xem thêm: Tương quan trong thống kê cho khoa học dữ liệu
Bây giờ, bằng seaborn, chúng ta sẽ xem phân bố của cột mean là như thế nào.
sb.displot(df["Mean"])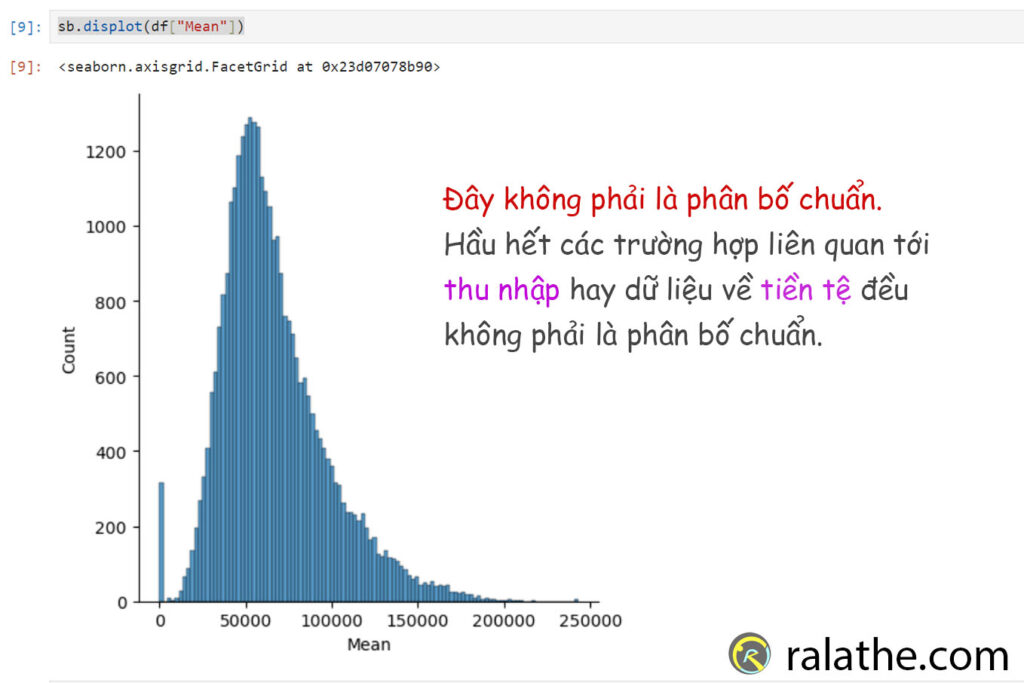
Chúng ta sẽ xem đây là phân bố của quần thể. Nhìn vào phân bố ta có thể thấy ngay đây không phải là phân bố chuẩn. Bây giờ chúng ta sẽ tính giá trị trung bình [math]\mu[/math] của quần thể này.
Chú ý 1: Thông thường ta sẽ không thể nào biết được [math]\mu[/math] của một quần thể.
Chú ý 2: Đây không phải là thu nhập trung bình của 1 hộ gia đình của nước Mỹ vì ta tính dựa trên thu nhập trung bình của mỗi tiểu bang chứ không phải thu nhập thực tế của 1 hộ gia đình.
Khi tính như thế ta cần tính đến trọng số của từng tiểu bang. Tuy nhiên, để đơn giản thì bài này ta sẽ xem đây là thu nhập trung bình của 1 hộ gia đình của Mỹ.
import numpy as np
np.mean(df["Mean"])
### Kết quả ###
66703.98604193568Ta thu được $66703 tức là khoảng gần 67 ngàn đô la một năm.
Bây giờ chúng ta sẽ thử ước lượng khoảng giá trị này theo từng bước ở trên.
>>>> Xem thêm: cá vàng có thể thông minh hơn bạn, bạn có tin không?
Ước lượng khoảng cho dataset này
Bước 1: Tạo mẫu dữ liệu (sample) bằng cách trích xuất ngẫu nhiên từ quần thể trên.
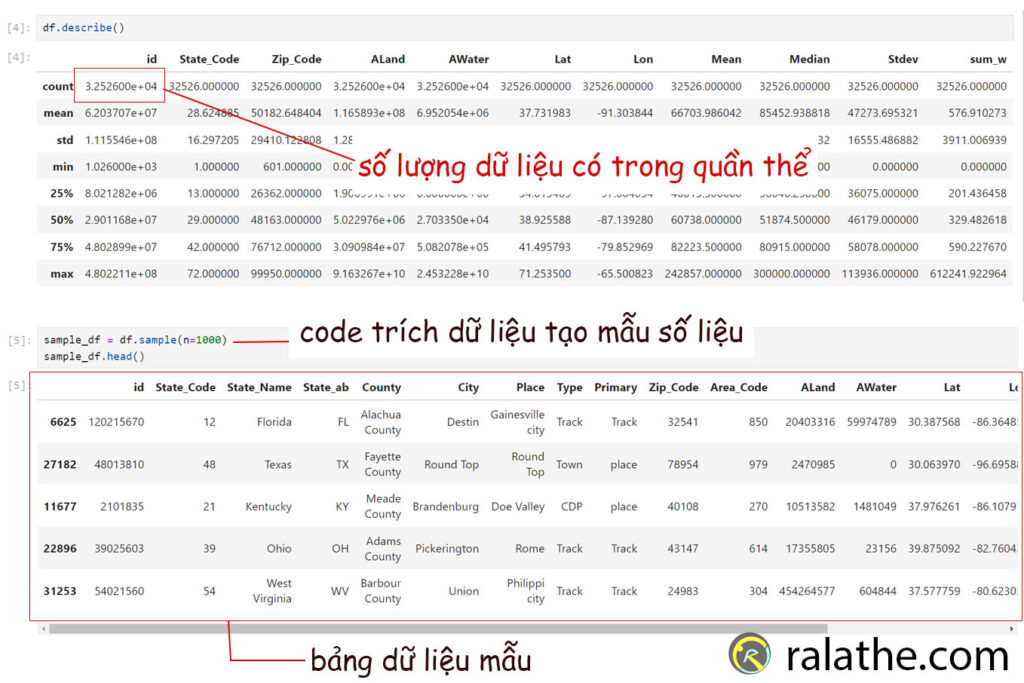
Từ mô tả trên ta thấy mẫu dữ liệu của quần thể có tổng cộng 32526 record. Từ đây, ta sẽ trích xuất ngẫu nhiên 1000 record để tạo mẫu dữ liệu.
sample_df = df.sample(n=1000)Tiếp theo chúng ta thử xem phân bố của mẫu là như thế nào.
sb.displot(sample_df["Mean"])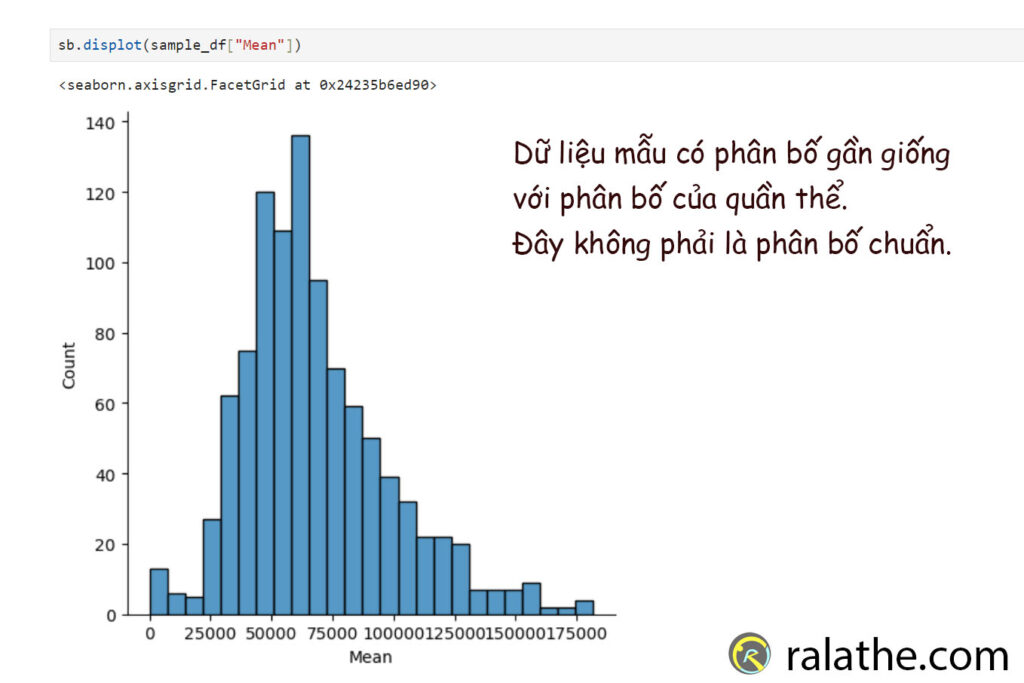
nó khá giống với phân bố của quần thể.
Bước 2: Tính công thức ước lượng mẫu
Vì ta đang ước lượng khoảng giá trị trung bình của quần thể. Nên công thức tính sẽ là giá trị trung bình của mẫu.
np.mean(sample_df["Mean"])Kết quả ra được 67968.913 đô la.
Bước 3: Xác định khoảng tinh cậy
Ở đây chúng ta sẽ lấy khoảng tin cậy là 95%.
Bước 4: xem xét phân bố mẫu của công thức ước lượng
Như ta đã nói ở trên, nếu quần thể có phân bố chuẩn, thì tất nhiên mẫu dữ liệu của chúng ta cũng sẽ có phân bố chuẩn. Nếu quần thể không có phân bố chuẩn thì ta sẽ cố gắng lấy mẫu sao cho [math]n[/math] là đủ lớn.
[math]n = 1000[/math] là có đủ lớn? Câu trả lời là có. Chi tiết sẽ được giải thích ở bài sau nhé!
Bước 5: Tính toán ước lượng khoảng giá trị cho [math]\mu[/math]
Bây giờ ta sẽ ước lượng dựa vào công thức đã có ở phần trên:
from scipy import stats
n=1000
sample_mean = np.mean(sample_df["Mean"]) # Trung bình của mẫu dữ liệu
sample_var=stats.tvar(sample_df["Mean"]) # phân tán bất biến thiên của mẫu dữ liệu
stats.norm.interval(confidence=0.95,loc=sample_mean,scale=np.sqrt(sample_var/n)) # khoảng trung bình của quần thểTa sẽ được kết quả: (66091.43789174319, 69846.38810825681). Nghĩa là ở độ tin cậy 95% (confidence = 0.95), thì [math]\mu[/math] của quần thể sẽ rơi vào khoảng $66,091~$69,846.
Ở trên, chúng ta đã tính được giá trị thực tế (!?) [math]\mu[/math] là $66,703. Do đó, ước lượng trên là chính xác.
Tổng kết
Ở bài này, chúng ta đã cùng nhau thực hiện việc ước lượng khoảng cho giá trị trung bình của một quần thể.
- Để ước lượng giá trị trung bình của quần thể, ta sử dụng giá trị trung bình dữ liệu mẫu làm công thức ước lượng.
- Khi [math]n[/math] đủ lớn, cho dù quần thể không có phân bố chuẩn thì mẫu dữ liệu cũng sẽ có phấn bố gần phân bố chuẩn.
Ước lượng khoảng cho giá trị trung bình có ba ý chính mà bạn cần nhớ:
- Phân bố của quần thể có phải là phân bố chuẩn hay không?
- Phân tán của quần thể đã biết hay chưa?
- Dữ liệu mẫu có độ lớn là bao nhiêu?