{kind=link}
Trong bài 9 của series thống kê cho khoa học dữ liệu chúng ta đã biết được cách ước lượng khoảng cho trung bình của quần thể. Bài này, hãy đi sâu hơn về phân bố t, một hân bố của quần thể nhé!
Mục lục bài viết
Phân bố t dùng trong thực tế thống kê cho khoa học dữ liệu
Ta đã biết, theo định lý giới hạn trung tâm, chỉ cần số lượng mẫu đủ lớn thì phân bố mẫu của giá trị trung bình sẽ có phân bố chuẩn dù cho quần thể có phân bố như thế nào.
Tuy nhiên, điều này chỉ đúng ta biết được phân tán của quần thể. Tuy nhiên, trong thực tế thì phân tán của quần thể là không biết trước được.
Khi đó, ta sử dụng phân tán bất biến thiên để thay thế. Chính vì thế, mà phân bố giá trị trung bình sẽ lệch đi một chút so với phân bố chuẩn.
Đây gọi là phân bố t.
Khái niệm về phân phối t
Ta đã biết công thức chuẩn hóa:
[math]z=\frac{\bar{x}-\mu}{\frac{\sigma}{n}}[/math]
Tuy nhiên, như đã nói ở trên, [math]\sigma[/math] của quần thể là chưa biết. Do đó, ta thay thế [math]\sigma[/math] bằng độ lệch bất biến thiên của dữ liệu mẫu [math]s'[/math] với:
[math]s’^2=\frac{1}{n-1}\displaystyle\sum_{i=1}^{n}(x_i-\bar{x})^2[/math]
phân bố với độ lệch bất biến thiên như vậy gọi là phân bố t.
[math]t=\frac{\bar{x}-\mu}{\frac{s’}{\sqrt{n}}}[/math]
Giải thích phân bố t
Phân bố chuẩn là phân bố có giá trị trung bình [math]\mu=0[/math] và độ lệch chuẩn [math]\sigma=1[/math]. Đây là phân bố không có đối số.
Tuy nhiên, với phân bố t, nó sẽ có hình dạng biến đổi tùy thuộc vào [math]n-1[/math]. Do đó, [math]n-1[/math] là đối số của phân bố t. Trong thống kê cho khoa học dữ liệu, người ta gọi [math]n-1[/math] này chính là bậc tự do (degree of freedom) của phân bố t.
Nhìn vào thực tế thống kê cho khoa học dữ liệu
Bây giờ chúng ta sẽ xem phân bố t trong thực tế như thế nào bằng vài lệnh python đơn giản nhé.
# import thư viện cần thiết
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
%matplotlib inline
# Vẽ phân bố t với bậc tự do từ 1 đến 10
x = np.linspace(-4,4,100)
for df in range (1,11):
t = stats.t.pdf(x,df)
plt.plot(x,t,label=f"df={df}")
plt.legend()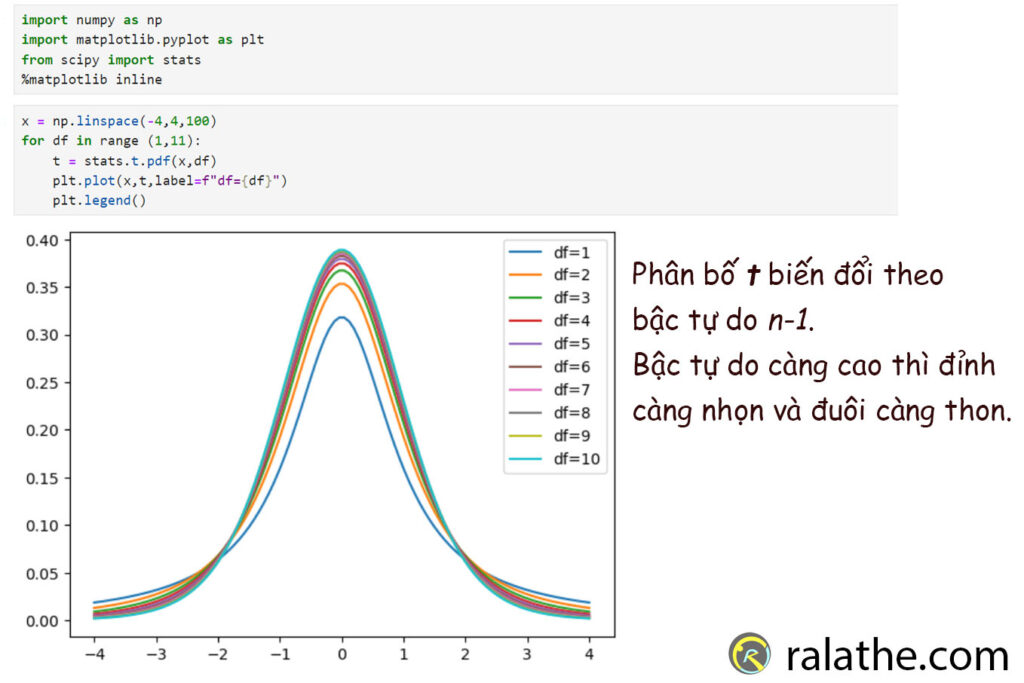
Ta có thể thấy, phân bố t cũng có dạng hình chuông, gần giống với phân bố chuẩn.
Nhìn vào hình có thể nhận ra, khi bậc tự do (df) càng lớn thì đáy sẽ hẹp, đỉnh nhọn hơn. Do đó, xác suất dữ liệu tập trung ở trung tâm càng lớn, và ngược lại.
>>>> Xem thêm: Tương quan pearson, một tương quan hay sử dụng
So sánh phân bố chuẩn và phân bố t
Bây giờ chúng ta hãy thử vẽ phân bố chuẩn và phân bố t trên cùng một đồ thị để xem sự khác nhau như thế nào nhé!
x = np.linspace(-4,4,100)
z = stats.norm.pdf(x,loc=0,scale=1) # phân phối chuẩn
for df in range(1,31,5): # phân phối t
t = stats.t.pdf(x,df)
plt.plot(x,t,label=f"phân bố t (df={df})")
plt.plot(x,z,label=f"phân bố chuẩn",linewidth=2,color="red",linestyle="dashed")
plt.legend();Chạy code này thì ta sẽ có được đồ thì như sau:
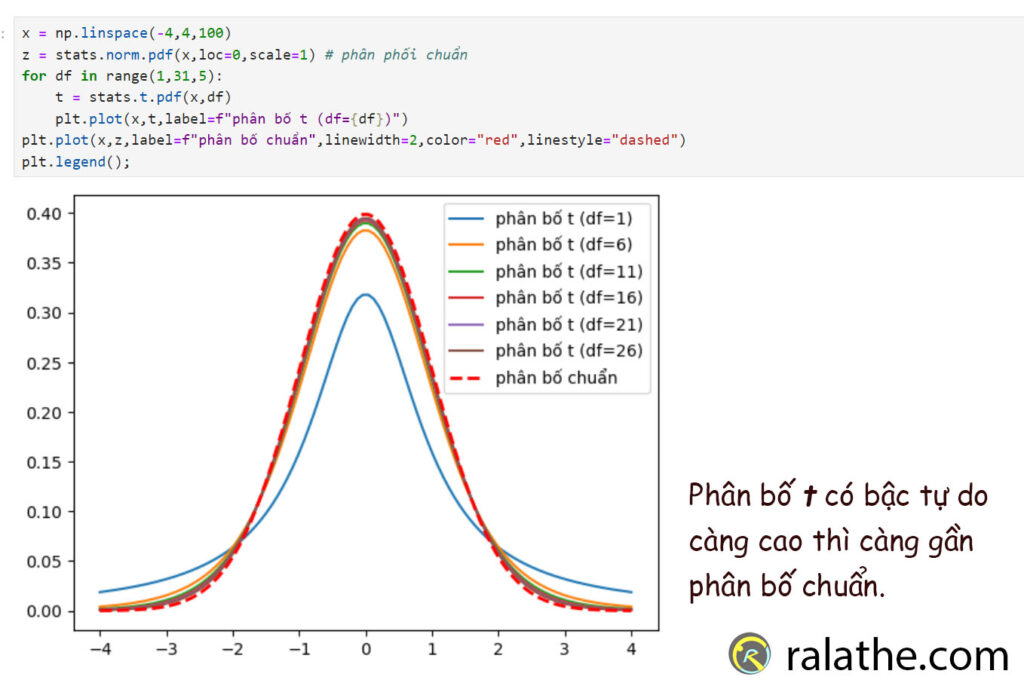
Đường màu đỏ gạch đứt chính là phân bố chuẩn. Như đã nói ở trên, khi bậc tự do [math]n-1[/math] càng tăng lên thì phân bố t càng gần với phân bố chuẩn.
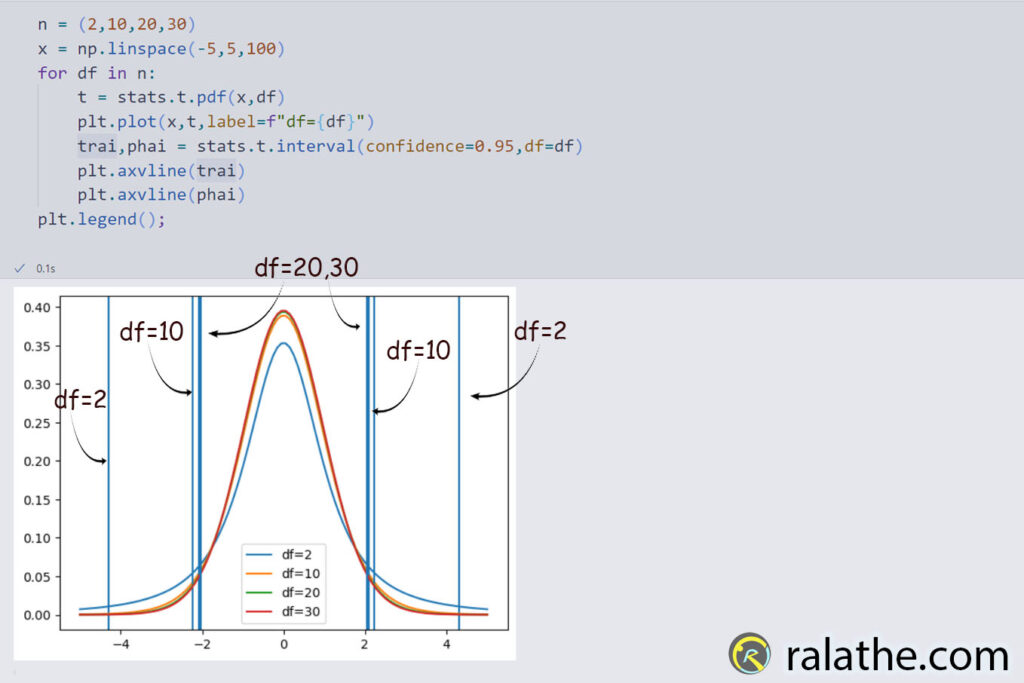
Như đã nói ở trên, khi bậc tự do càng nhỏ thì đáy càng rộng. Điều này có nghĩa là khoảng CI 95% sẽ càng rộng hơn. Hãy thử xét khoảng CI của phân bố t có bậc tự do là 2 và phân bố chuẩn nhé.
Phân bố chuẩn:
# CI = 95% của phân bố chuẩn
x = np.linspace(-3,3,100)
trai,phai = stats.norm.interval(confidence=0.95,loc=0,scale=1)
z = stats.norm.pdf(x,loc=0,scale=1)
plt.plot(x,z)
plt.axvline(trai,color='red')
plt.axvline(phai,color='red')
print(trai,phai)Kết quả: CI = (-1.959963984540054 1.959963984540054) đúng như những gì chúng ta đã bàn, ở khoảng tin cậy 95% sẽ nằm trong khoảng từ (-1.96,1.96)
Phân bố t (df=2):
# CI = 95% của phân bố t
x = np.linspace(-5,5,100)
trai,phai = stats.t.interval(confidence=0.95,df=2)
t = stats.t.pdf(x,df=2)
plt.plot(x,t)
plt.axvline(trai,color='red')
plt.axvline(phai,color='red')
print(trai,phai)Kết quả: CI = (-4.302652729911275 4.302652729911275). Khoảng tin cậy 95% đã được mở rộng ra đến (-4.3,4.3) khi bậc tự do df = 2 (tức n=3).
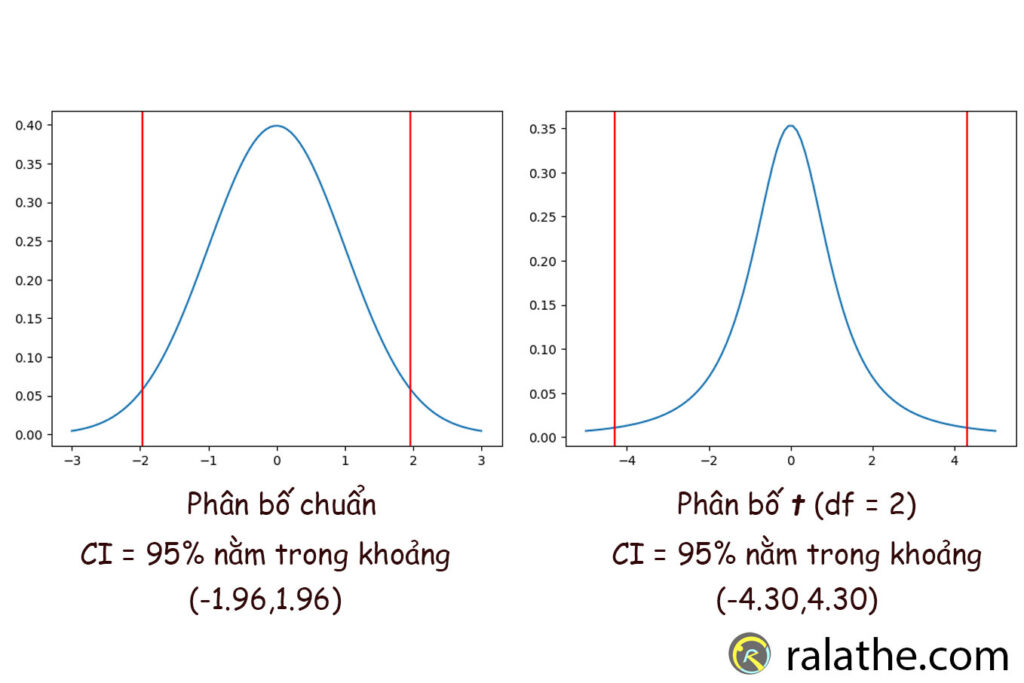
Vì diện tích của hình chuông bao giờ cũng là 1, nên khi bậc tự do tăng lên, làm tăng xác xuất xuất hiện ở trung tâm. Do đó, đỉnh sẽ nhọn hơn và đáy sẽ được thu hẹp, nên khoảng tin cậy sẽ hẹp lại.
Chính vì thế, khi kích thước của mẫu càng lớn thì khoảng tin cậy sẽ càng hẹp và tiến dần về khoảng (-1.96,1.96) của phân bố chuẩn.
Ước lượng khoảng giá trị trung bình của quần thể
Tương tự như bài trước của series thống kê cho khoa học dữ liệu, bài này chúng ta cũng sẽ dùng bộ dataset US Household income statistics.
Ta cũng sẽ nhập bảng số liệu vào python và tính toán giá trị trung bình của quần thể như ở bài trước.
import pandas as pd
import seaborn as sb
import numpy as np
df = pd.read_csv("./data/kaggle_income.csv", encoding="ISO-8859-1")
np.mean(df["Mean"]) #tính toán trung bình của quần thể nàyKết quả được là: 66703.98604193568, tức là khoảng $66,703.
Bây giờ chúng ta cũng sẽ trích xuất từ quần thể này ra 1 mẫu số liệu có [math]n=1000[/math].
n = 1000 # số lượng mẫu cần trích xuất từ quần thể
sample_df = df.sample(n=n)Bây giờ ta sẽ dùng phân bố t để ước lượng khoảng giá trị trung bình của quần thể từ mẫu đã trích xuất:
from scipy import stats
sample_mean = np.mean(sample_df["Mean"]) # trung bình của mẫu
sample_std = stats.tstd(sample_df["Mean"]) # độ lệch chuẩn của mẫu
stats.t.interval(confidence=0.95, loc=sample_mean, scale=sample_std/np.sqrt(n), df=n-1)Kết quả đạt được: (66066.55112863184, 69866.11087136818), tức là giá trị trung bình của quần thể nằm trong khoảng $66,066 đến $69,866.
Ta thấy giá trị thực tế của quần thể là $66,703, nằm trong khoảng ta đã ước lượng.
Dùng phân bố t hay phân bố chuẩn?
Trong thực tế thống kê cho khoa học dữ liệu, khi dữ liệu mẫu có kích thước lớn, phân bố t sẽ gần với phân bố chuẩn nên người ta thường dùng phân bố chuẩn vì nó đơn giản và tiện lợi.
Tuy nhiên, khi không biết độ lệch của quần thể, thì phân bố t vẫn là một lựa chọn tốt nhất.