{kind=link}
Tương quan spearman – một tương quan thay thế cho Pearson. Chào các bạn, lâu quá rồi không viết bài, phần vì chuyển nơi làm việc, phần vì lười 🤣. Hôm nay, mới thi xong, công việc tạm thời ổn định (vì nhiều quá chưa biết làm từ đâu) nên mình sẽ đi tiếp loạt bài thống kê cho khoa học dữ liệu cực kỳ cơ bản này nhé.
Trong bài trước chúng ta đã tìm hiểu về đồng phương sai và tương quan Pearson, một mô hình được ứng dụng rất nhiều trong cuộc sống. Tuy nhiên sẽ có lúc tương quan Pearson không đáp ứng được yêu cầu. Khi đó chúng ta cần một tương quan khác phù hợp hơn. Trong bài hôm này, chúng ta sẽ cùng tìm hiểu về tương quan Spearman (Spearman’s Rank correlation) nhé.
Mục lục bài viết
Điểm yếu của tương quan Pearson trong thống kê cho khoa học dữ liệu
Trong bài trước, chúng ta đã biết, tương quan Pearson rất hiệu quả nhưng chỉ với tương quan tuyến tính, nghĩa nằm trên một đường thẳng. Tuy nhiên, nếu các điểm dữ liệu có sự tương quan với nhau nhưng không nằm trên một đường thẳng thì sao? Lúc này tương quan Pearson sẽ thể hiện điểm yếu của mình.
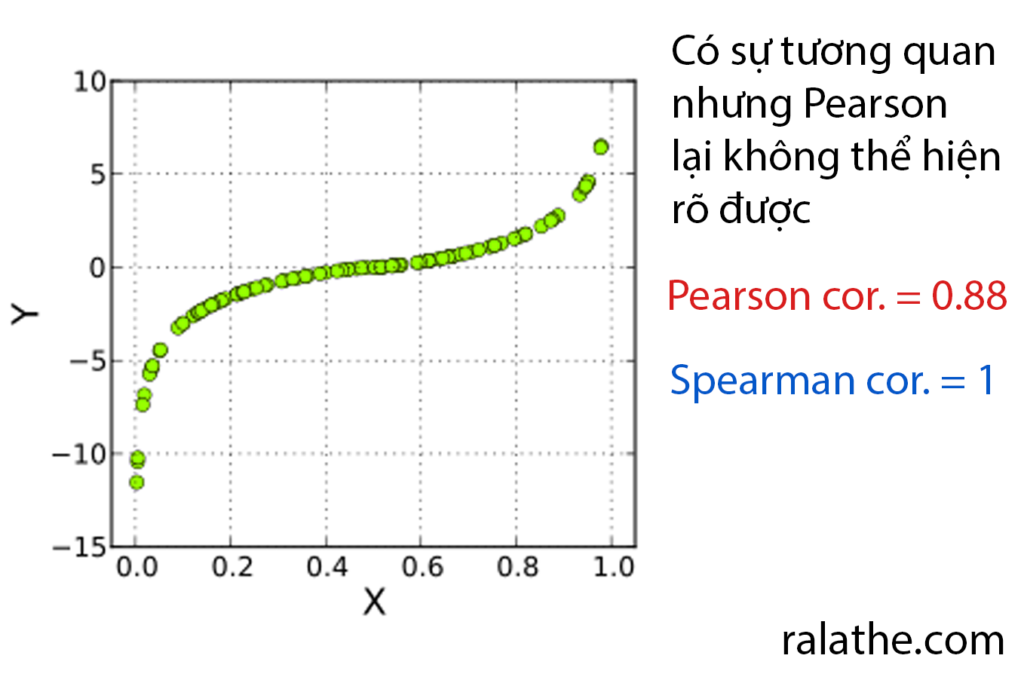
Như bạn có thể thấy hình ở trên, rõ ràng có sự tương quan chặc chẽ giữa X và Y nhưng Pearson lại không thể hiện rõ được mối liên hệ này.
Do đó, nếu gặp trường hợp như thế, thường thì người ta sẽ sử dụng một công thức khác để thể hiện mối tương quan. Một trong số đó chính là tương quan xếp hạng Spearman.
Tương quan Spearman trong thống kê cho khoa học dữ liệu
Để có thể hiểu hơn về tương quan xếp hạn Spearman (gọi tắt là tương quan Spearman), hãy cùng nhau xét một ví dụ như sau:
| Điểm toán | Điểm lý | Xếp hạng điểm toán (t) | Xếp hạng điểm lý (l) | Tương quan xếp hạng (d) |
| 8 | 9 | 2 | 1 | 2 – 1 = 1 |
| 6 | 5 | 4 | 4 | 4 – 4 = 0 |
| 4 | 3 | 5 | 5 | 5 – 5 = 0 |
| 10 | 8 | 1 | 2 | 1 – 2 = -1 |
| 7 | 6 | 3 | 3 | 3 – 3 = 0 |
| 2 | 1 | 7 | 7 | 7 – 7 = 0 |
| 3 | 2 | 6 | 6 | 6 – 6 = 0 |
Để xét xem điểm toán và lý có sự tương quan với nhau hay không bằng tương quan Spearman. Chúng ta sẽ xếp hạng các điểm số. Điểm cao nhất sẽ là hạng 1, và tăng lên từ từ như bảng trên, ở cột (3) xếp hạng điểm toán, và cột (4) xếp hạng điểm lý.
Bây giờ, để có thể xét được sự tương quan giữa toán và lý, chúng ta sẽ thêm một cột nữa, gọi là cột tương quan giữa xếp hạng của điểm toán và điểm lý (cột d).
Khi đó cột d sẽ được tính là [math]d=t-l[/math] (vì chúng ta đang tìm sự tương quan giữa hạng của toán và lý)
Công thức tính tương quan spearman
Hệ số tương quan Spearman [math]r_s[/math] lúc này sẽ được tính theo công thức:
[math]r_s = 1 – \frac{6\sum{d^2}}{n(n^2-1)}[/math]
n chính là tổng số phần tử của mẫu, trong ví dụ này thì n = 7.
Từ đó ta có thể tính được hệ số Spearman của điểm toán và lý như sau:
[math]r_s = 1 – \frac{6 \times 2}{7(7^2-1)} = 0.9643[/math]
Trong thống kê cho khoa học dữ liệu, chúng ta đã biết, hệ số tương quan sẽ chạy từ -1 (tương quan nghịch), đến 0 (không có sự tương quan nào) và đến 1 (tương quan thuận). Ở đây ta thấy, [math]r_s = 0.9643[/math], tức là giữa điểm toán và điểm lý có một sự tương quan thuận chặc chẽ. Hay nói cách khác, điểm toán mà tăng thì điểm lý cũng tăng và ngược lại.
Ở đây, nếu chúng ta tính theo hệ số Pearson thì ta sẽ được kết quả: [math]\rho = 0.9547[/math]. Cũng cao nhỉ 🤣🤣
Tuy nhiên, có những lúc khi tính bằng hệ số Pearson sẽ cho kết quả rất thấp nhưng khi nhìn vào chúng ta biết là có một sự tương quan nào đó giữa hai số liệu, thì hệ số Spearman sẽ là một sự lựa chọn thay thế không tồi, đúng không nào.
Tính hệ số Spearman khi có tied rank
Tied rank là gì?
Trong ví dụ ở trên, xếp hạng của những điểm số là không trùng nhau (nghĩa là không có điểm nào đồng hạng với nhau) thì ta có thể sử dụng công thức như trên. Tuy nhiên, trong thực tế, khi làm thống kê cho khoa học dữ liệu, chúng ta sẽ không ít lần bắt gặp những phần tử đồng hạng với nhau. Khi đó chính là tied rank.
Hãy xem ví dụ bên dưới:
| Điểm toán | Điểm lý | Xếp hạng điểm toán (t) | Xếp hạng điểm lý (l) |
| 10 | 9 | 1 | 1 |
| 9 | 8 | 2 | 2 |
| 7 | 6 | 3 | 3 |
| 5 | 6 | 4 | 3 |
| 4 | 3 | 5 | 4 |
Ở đây chúng ta thấy, lý có đồng hạng 3. Đây được gọi là tied rank. Để có thể tính được hệ số tương quan, thì một phần tử sẽ có hạng 3, phần tử còn lại có hạng tiếp theo, là hạng 4. Khi đó, xếp hạng của 2 phần tử này sẽ là trung bình cộng của nó, chính là 3.5. Chúng ta có bảng sau:
| Điểm toán | Điểm lý | Xếp hạng điểm toán(t) | Xếp hạng điểm lý(l) |
| 10 | 9 | 1 | 1 |
| 9 | 8 | 2 | 2 |
| 7 | 6 | 3 | 3.5 |
| 5 | 6 | 4 | 3.5 |
| 4 | 3 | 5 | 5 |
Khi đó, công thức tính hệ số tương quan Spearman khi có tied rank sẽ là:
[math]r_s = \frac{\sum{(x – \bar{x})(y – \bar{y})}}{\sqrt{\sum{(x – \bar{x})^2\sum{(y-\bar{y})^2}}}}[/math]
Công thức thì có vẻ phức tạp, tuy nhiên, sau này khi làm thống kê cho khoa học dữ liệu, chúng ta toàn dùng R hoặc python thôi, không cần để ý lắm 😜😜
Quay lại ví dụ trên, khi đó: [math]r_s = 0.9747[/math].
Cách tính tương quan spearman bằng code
Ta có thể dùng code này để tính hệ số Spearman trong R:
> diemToan = c(10, 9, 7, 5, 4)
> diemLy = c(9, 8, 6, 6, 3)
> ### Spearman's rank
> cor(diemToan, diemLy, method = "spearman")
### kết quả ###
[1] 0.9746794hoặc tính trong python thì dùng code:
import numpy as np
import scipy.stats as st
diemToan = np.array([10, 9, 7, 5, 4])
diemToan = np.array([10, 9, 7, 5, 4])
## Spearman's rank
r_s = st.spearmanr(diemToan, diemLy)
r_s
### Kết quả ###
SignificanceResult(statistic=0.9746794344808964, pvalue=0.004818230468198537)Lợi ích của tương quan Spearman
Qua những ví dụ trên, chúng ta cũng đã thấy được lợi ích của tương quan xếp hạng Spearman rồi phải không? Hãy cùng xem lại nhé:
- Khi tương quan Pearson không chính xác thì Spearman sẽ là sự thay thế
- Tương quan Spearman không bị ảnh hưởng bởi outlier do chúng ta tính toán bằng cách xếp hạng, không phải dựa vào giá trị của phần tử.
Khác biệt giữa tương quan Spearman và tương quan Pearson
Trong thống kê cho khoa học dữ liệu, khác với tương quan Pearson, tương quan Spearman được sử dụng trong kiểm định phi tham số (non-parametric).
Kiểm định có tham số chẳng hạng như: T-test, ANOVA
Kiểm định phi tham số như: Mann-Whitney U-Test hay là Wilcoxon-Test.
Những vấn đề về kiểm định sẽ được làm rõ trong phần 2 của series thống kê cho khoa học dữ liệu này nhé.
Và vì thế, khi tính toán tương quan Spearman, dữ liệu không được phép có phân bố chuẩn và kiểu dữ liệu phải là ordinal (dữ liệu có thể xếp hạng được) (xem lại bài 2 của series này nhé!)
Video thống kê cho khoa học dữ liệu bài 6
Hi vọng các bạn đã có thêm cho mình một công cụ nữa để tìm sự tương quan khi làm thống kê cho khoa học dữ liệu nhé. Chúc các bạn thành công và hẹn gặp các bạn trong bài tiếp theo của series cơ bản về data science này.
>>>> Xem thêm: Bài 4, cơ bản về xác suất trong thống kê cho khoa học dữ liệu