{kind=link}
Những khái niệm và kiến thức thống kê cho khoa học dữ liệu giúp bạn làm quen với môn thống kê hướng tới data science và máy học.
Mục lục bài viết
Khái niệm về thống kê
Thống kê là môn nghiên cứu về dữ liệu, chúng ta sẽ thu thập dữ liệu, phân tích và xử lý để có thể hiểu hơn về dữ liệu. Thống kê chia ra làm hai nhánh chính:
- Thống kê mô tả: giúp mô tả, hình ảnh hóa số liệu qua biểu đồ, từ đó tìm kiếm xu hướng của số liệu.
- Thống kê suy diễn: từ những mẫu nhỏ, giúp chúng ta tìm ra tính chất chung của toàn thể (population).
Thống kê cho khoa học dữ liệu: thống kê mô tả
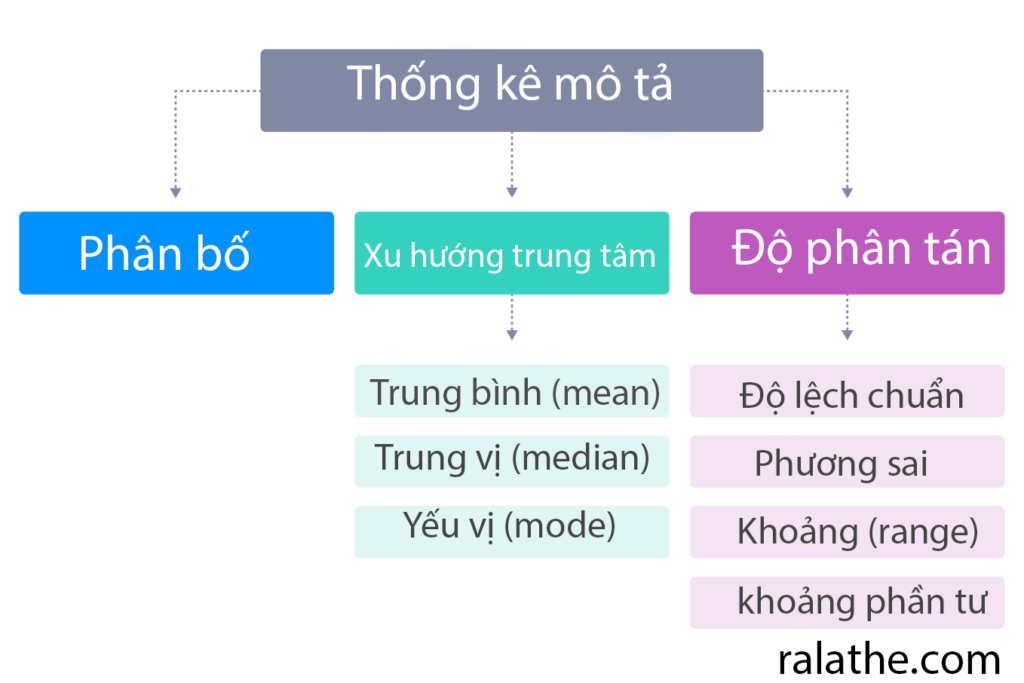
Thống kê mô tả (Descriptive Statistics) là các hệ số mô tả ngắn gọn hay tóm tắt một tập dữ liệu nhất định, có thể là đại diện cho toàn bộ hoặc một mẫu của một tổng thể.
Thống kê mô tả được chia thành đo lường xu hướng tập trung và đo lường biến động. Đo lường xu hướng tập trung có giá trị trung bình, trung vị và mode (yếu vị), trong khi các đo lường biến động gồm độ lệch chuẩn, phương sai, giá trị nhỏ nhất và giá trị lớn nhất, độ nhọn và độ lệch.
Thống kê cho khoa học dữ liệu: thống kê suy diễn
Thống kê suy diễn (Inferential statistics) là cách chúng ta sử dụng toán học để đánh giá thông tin từ một phần nhỏ của dữ liệu và từ đó, chúng ta có thể đưa ra những suy luận tổng quát về toàn bộ tập dữ liệu. Điều này giúp chúng ta xác định mức độ tin cậy của những suy luận đó.
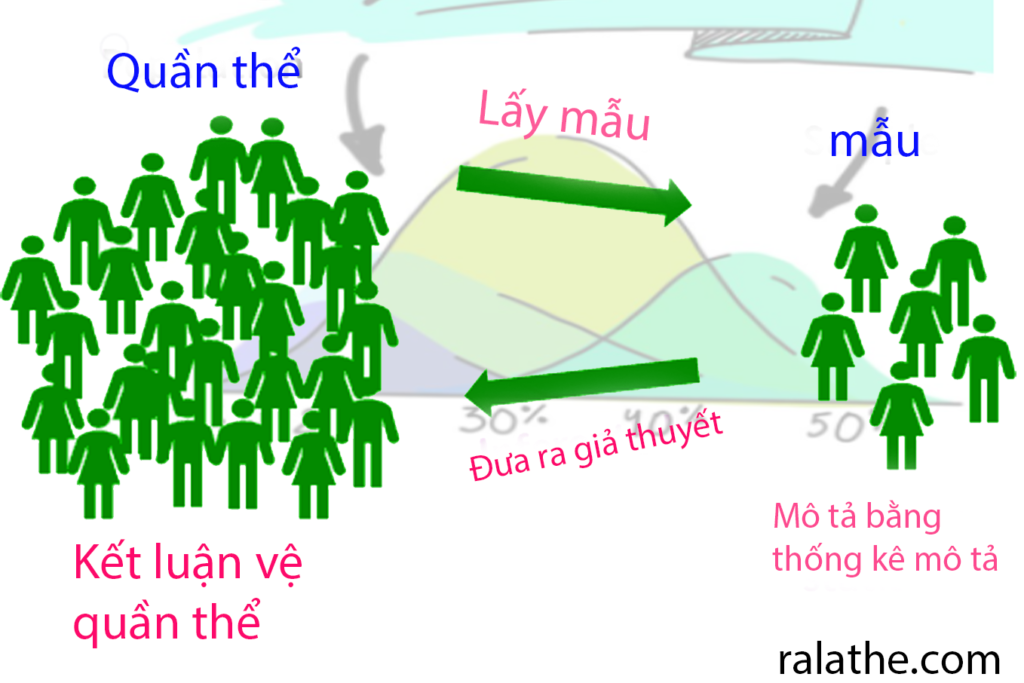
Khi nghiên cứu, chúng ta thường đặt ra những giả định (giả thuyết) về các đặc điểm của toàn bộ nhóm mà chúng ta muốn biết đến. Thống kê suy luận giúp chúng ta kiểm tra xem những giả định này có được chấp nhận hay không.
Mục tiêu chính của thống kê suy luận là khám phá và hiểu rõ những điều quan trọng từ dữ liệu mẫu, với ý nghĩa là chúng ta muốn hiểu thêm về toàn bộ tập dữ liệu mà chúng ta không thể kiểm soát trực tiếp. Chúng ta thường áp dụng thống kê suy luận khi muốn đưa ra ước lượng về những số liệu quan trọng trong các lĩnh vực như lương học, dân số học và nhiều lĩnh vực khác.
>>>> Xem thêm: Sửa lỗi khi cài đặt R cho máy để học thống kê
Cách thức lấy mẫu
Có 4 phương pháp lấy mẫu thống kê chính, đó là:
- Random (lấy mẫu ngẫu nhiên)
- Systematic (lấy mẫu hệ thống)
- Stratified (lấy mẫu theo lớp)
- Cluster
Lấy mẫu ngẫu nhiên
Như tên gọi của nó, trong thống kê cho khoa học dữ liệu, lấy mẫu ngẫu nhiên chính là từ trong quần thể, chọn ngẫu nhiên ra một số lượng các mẫu. Trong phương pháp lấy mẫu này, mỗi phần từ (element) trong quần thể (population) đều có một cơ hội chính xác như nhau để được chọn.
Phương pháp này là phương pháp lấy mẫu xác suất đơn giản nhất, vì nó chỉ liên quan đến một lựa chọn ngẫu nhiên duy nhất và yêu cầu ít kiến thức trước về quần thể. Bởi vì nó sử dụng nguyên tắc ngẫu nhiên, bất kỳ nghiên cứu nào thực hiện trên mẫu này đều nên có tính tin cậy nội và ngoại vi cao, và ít có rủi ro về các độ chệch nghiên cứu như độ chệch lấy mẫu và độ chệch chọn lọc.
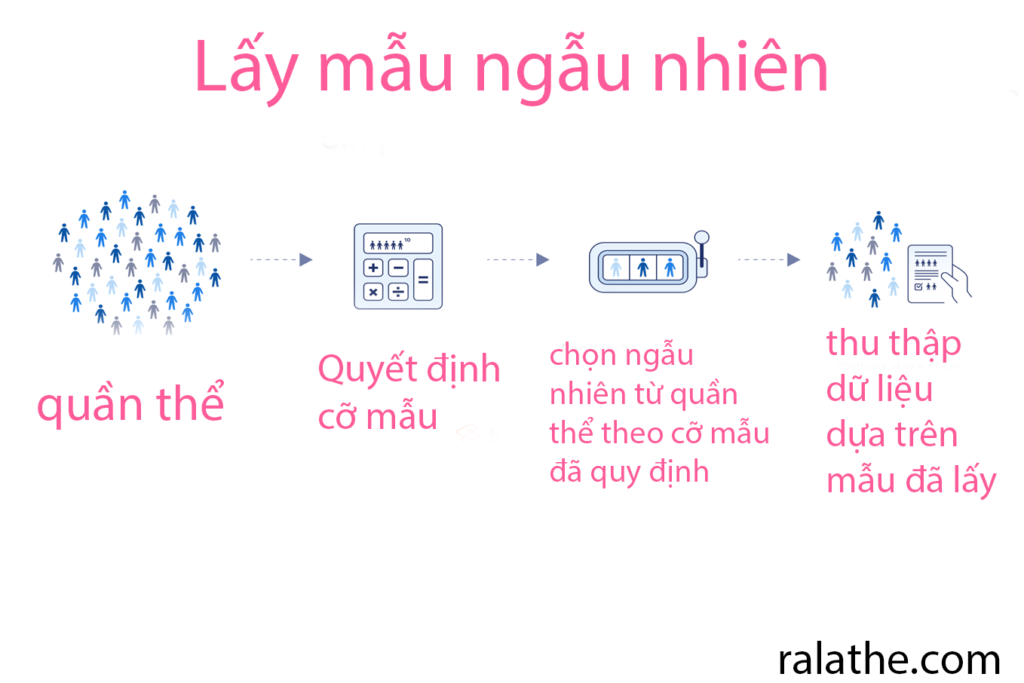
Ví dụ: Trong trang trại nuôi 30,000 con bò sữa. Từ trang trại đó bạn chọn ngẫu nhiên 300 con bò sữa để lấy mẫu về cân nặng, chất lượng sữa, tình trạng sức khỏe của bò để đánh giá trạng thái hoạt động của trang trại là tốt hay không.
Lấy mẫu hệ thống
Trong Thống kê cho khoa học dữ liệu, cách lấy mẫu thứ 2 chính là lấy mẫu theo hệ thống. Lấy mẫu hệ thống là một phương pháp lấy mẫu xác suất, trong đó các nhà nghiên cứu chọn lựa các cá thể của quần thể ở một khoảng cách đều (k nào đó) được xác định trước.
Nếu thứ tự của quần thể là ngẫu nhiên hoặc giống ngẫu nhiên (ví dụ, theo thứ tự chữ cái), thì phương pháp này sẽ mang lại một mẫu đại diện có thể được sử dụng để rút ra kết luận về quần thể bạn quan tâm.
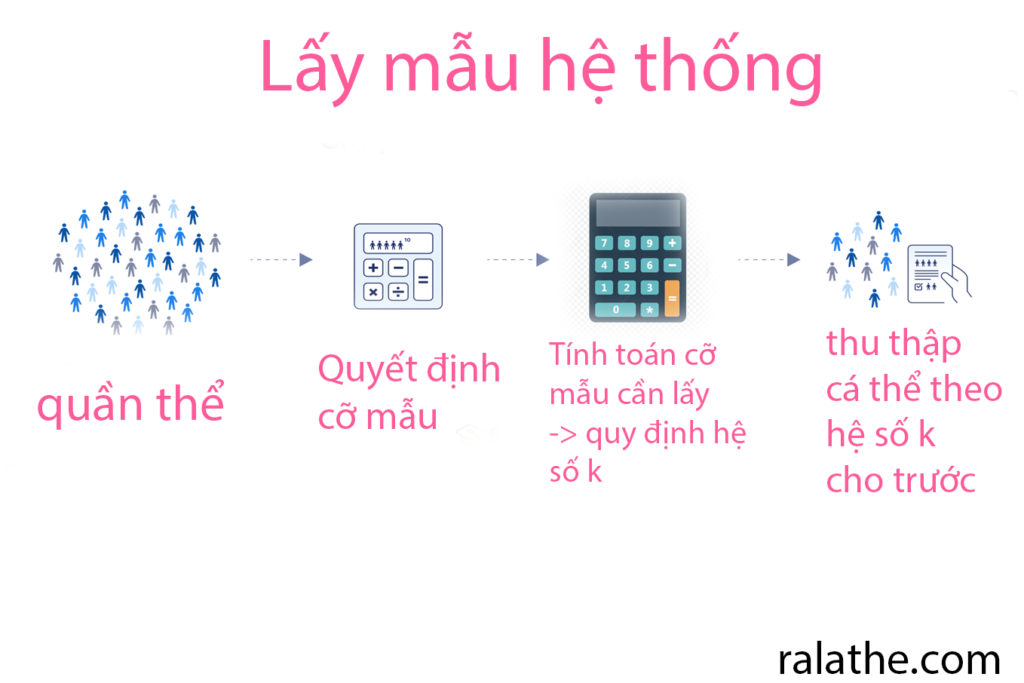
Ví dụ: trang trại bò ở trên, thay vì thả toàn bộ 30,000 con bò và bắt một cách ngẫu nhiên, họ sẽ đưa ra một quy định, đó là cho bò đi qua một hàng rào, cứ 100 con bò thì bắt ra một con để làm mẫu, sao cho đủ 300 con thì dừng (ở đây hệ số k sẽ là 100).
Lấy mẫu theo lớp
Trong một mẫu theo lớp, nhà nghiên cứu chia một quần thể thành các phân nhóm đồng nhất được gọi là các lớp (strata – số nhiều của stratum) dựa trên các đặc điểm cụ thể (ví dụ, chủng tộc, giới tính, địa điểm, v.v.). Mỗi thành viên của quần thể nghiên cứu phải thuộc một và chỉ một lớp.
Sau đó, mỗi lớp được lấy mẫu bằng cách sử dụng một phương pháp lấy mẫu xác suất khác, như lấy mẫu theo cụm hoặc lấy mẫu ngẫu nhiên đơn giản, cho phép nhà nghiên cứu ước tính các chỉ số thống kê cho mỗi phụ quần thể.
Nhà nghiên cứu sử dụng mẫu theo lớp khi các đặc điểm của quần thể đa dạng và họ muốn đảm bảo rằng mỗi đặc điểm được đại diện đúng cách trong mẫu. Điều này giúp nâng cao khả năng tổng quát và tính chính xác của nghiên cứu, đồng thời tránh các độ chệch nghiên cứu như độ chệch thiếu sót thông tin.
>>>> Fun fact: Nhìn chó biết mặt chủ, đoán tính cách qua việc nuôi chó
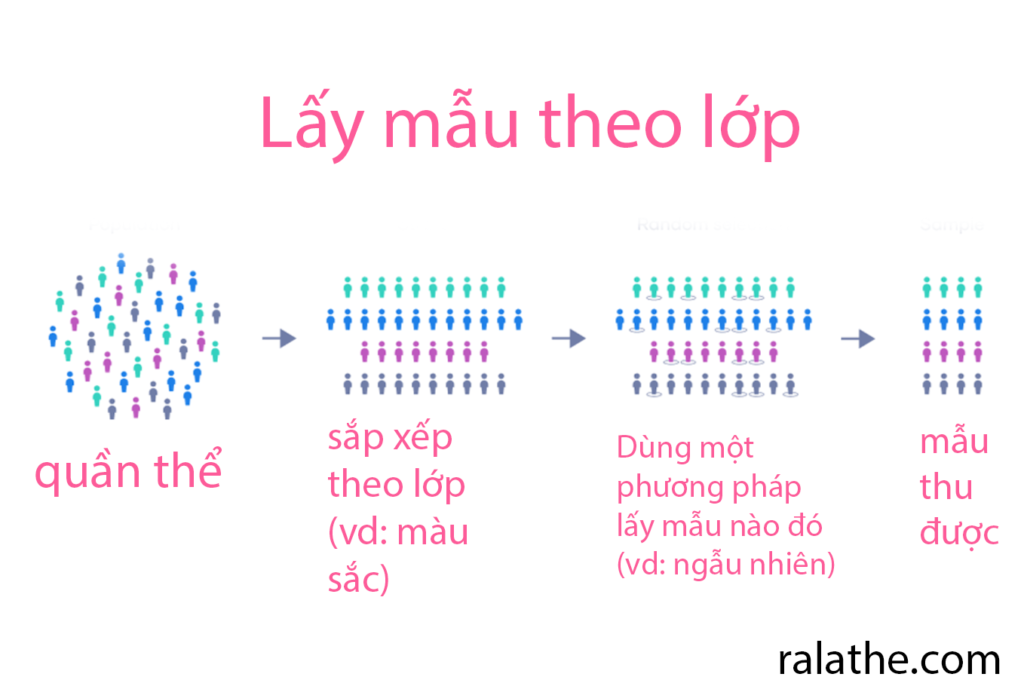
Ví dụ: Ở trang trại bò trên, chúng ta có thể chia ra thành các lớp như bò vừa mới cho sữa, bò cho sữa trong vòng 3 năm, và bò cho sữa trên 3 năm. Từ 3 lớp đó, chọn ngẫu nhiên ra một số lượng bò nhất định đưa vào thành 1 mẫu.
Ví dụ 2: giả sử bạn đang điều tra tỉ lệ ưa thích về một sản phẩm nào đó. Bạn cần phải chia ra đối tượng điều tra của mình, chẳng hạn: nam, nữ, còn đi học, đã có gia đình, có việc làm, làm nội trợ, v.v. vì xu hướng tiêu dùng của những nhóm đối tượng đó là khác nhau. Chính vì thế cần phải phân lớp ra để lấy mẫu thì mới có thể đại diện chính xác cho quần thể được.
Cluster (lấy mẫu theo cụm) một cách lấy mẫu thống kê cho khoa học dữ liệu
Trong lấy mẫu theo cụm, nhà nghiên cứu chia một quần thể thành các nhóm nhỏ được biết đến là cụm (cluster). Sau đó, họ chọn ngẫu nhiên giữa những cụm này để tạo thành một mẫu. Đây là một phương pháp phổ biến trong thống kê cho khoa học dữ liệu mà bạn thường thấy.
Lấy mẫu theo cụm là một phương pháp lấy mẫu xác suất thường được sử dụng để nghiên cứu các quần thể lớn, đặc biệt là những quần thể phân tán địa lý rộng rãi. Thông thường, nhà nghiên cứu sử dụng các đơn vị có sẵn như các trường học hoặc thành phố làm các cụm.”
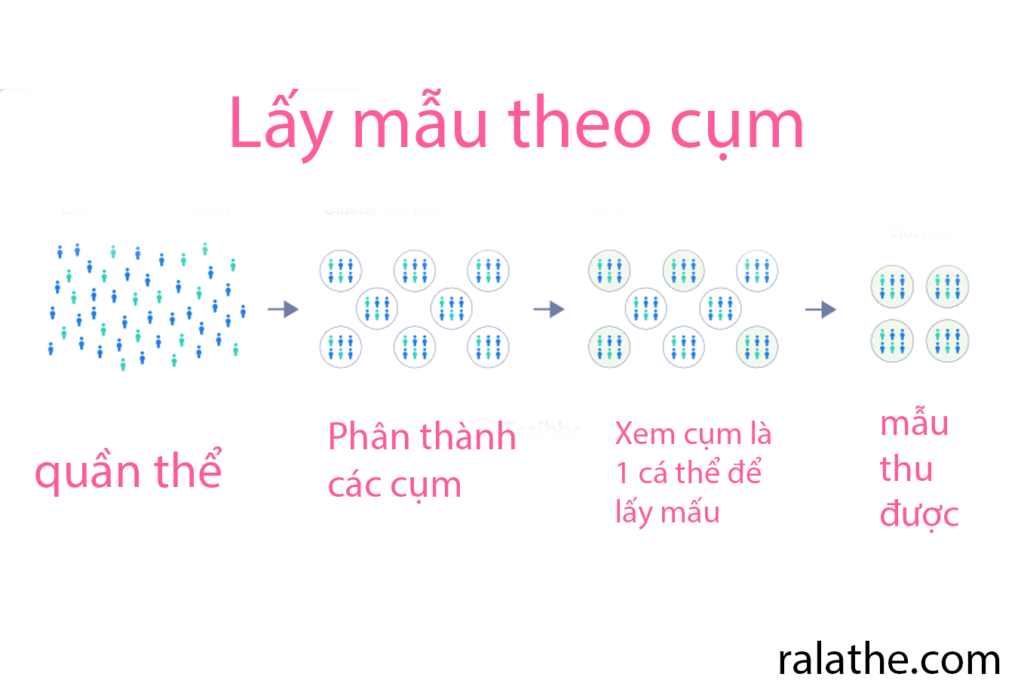
Ví dụ: Bạn được giao cho việc lấy mẫu điều tra về xu hướng tiêu dùng một mặt hàng ở trong nước Việt Nam. Khi đó, bạn có thể phân chia ra thành nhiều cụm (chẳng hạn 63 cụm tương đương với 63 tỉnh thành) rồi từ những cụm đó, chọn ra ngẫu nhiên vài cụm để khảo sát. Đây được gọi là lấy mẫu theo cụm.
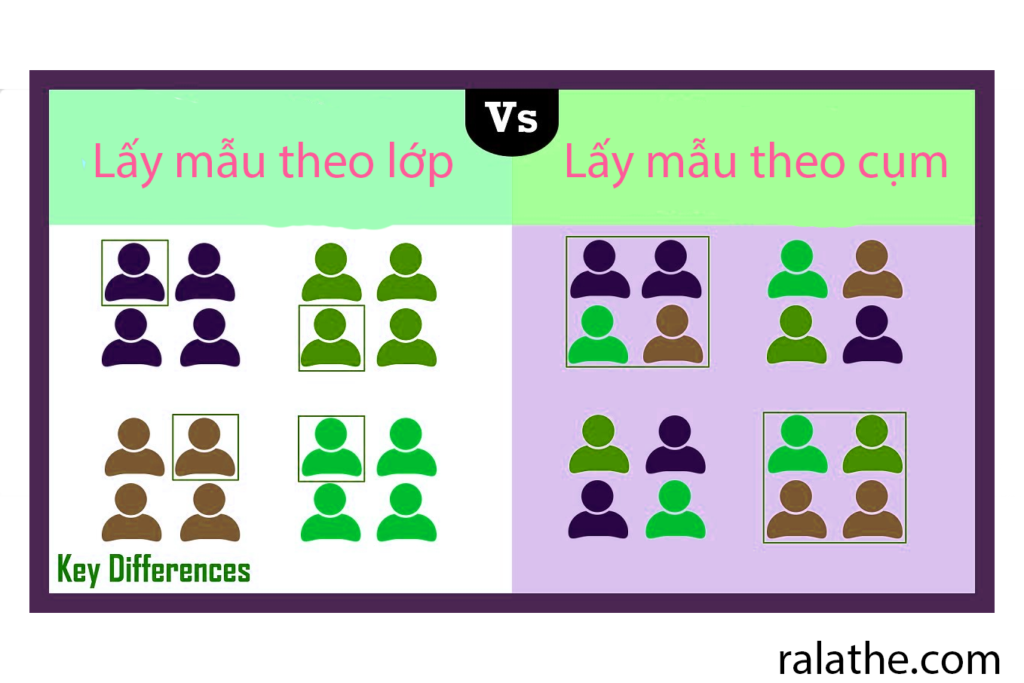
Trong Thống kê cho khoa học dữ liệu hay data science, giữa lấy mẫu theo cụm và theo lớp khác nhau như thế nào? Bạn có thể hình dùng là nếu lấy mẫu theo lớp thì từ những lớp đó mình sẽ chọn ra những phần tử để gọp lại thành 1 mẫu. Tuy nhiên, khi lấy mẫu theo cụm thì chúng ta sẽ xem 1 cụm đó là 1 cá thể để gọp lại thành một mẫu của chúng ta.
Video bài giảng cho bài Thống kê cho khoa học dữ liệu: bài 1
Nếu bạn thích xem bằng video hơn thì hãy cùng tìm hiểu qua video dưới đây nhé!